#软硬件环境
Ubuntu 24.04
双路8259CL
DDR4 2400 LRDIMM 768G
NUMA节点:关闭 GPT-OSS-120b是OpenAI 的开源权重(open-weight)MoE 推理模型,36 层、总参约 116.8B,每 token 激活参数约 5.13B,MoE 权重用 MXFP4(4.25 bit) 量化,整模权重(checkpoint)约 60.8 GiB;MoE 采用 128 专家、top-4 路由,注意力为 64 Q heads / 8 KV heads(GQA),head_dim=64,最长上下文 128k。
单token理论速度计算:
权重读流量(与上下文 L 无关):
激活参数约 5.13B / token,可由下式近似分解:
MoE-MLP:总 114.71B,top-4/128 → 激活 114.71B×(4/128)=3.5847B;MXFP4=0.53125 B/param → ≈1.904 GB/token
Attention 参数:0.96B × 2 B ≈ 1.920 GB/token(按 bf16/fp16 估)
Unembed:(1.16B/2) × 2 B ≈ 1.160 GB/token
合计权重读 ≈ 4.98 GB/token(≈4.64 GiB/token)。
但是Cascade Lake不支持FP16/BF16,只能以FP32存,因此 ≈ 8.064 GB/token
KV Cache 读/写(与上下文 L 线性相关):
每层每个 token 的 K、V 向量:2 * H_kv * d = 2*8*64 = 1024 元素,按 2 B/elem → 2048 B/层·token。
对于全局层(18 层):读 2048 * L/层;窗口层(18 层, 窗口=128):读 2048 * 128/层;
写入(所有 36 层):每新 token 写入当前的 K、V:36 * 2048 = 73,728 B ≈ 72 KiB/token(相对读流量可忽略)。
上下文和带宽的关系
| 上下文 L | FP16 权重读 (GB) | FP16 KV (GB) | FP16合计 (GB/token) | FP32 KV (GB) | FP32 权重读 (GB) | FP32合计 (GB/token) |
| 8k | 4.984 | 0.307 | 5.291 | 0.6136 | 8.064 | 8.678 |
| 32k | 4.984 | 1.213 | 6.197 | 2.4255 | 8.064 | 10.490 |
| 128k | 4.984 | 4.837 | 9.821 | 9.6733 | 8.064 | 17.737 |
1、环境准备:
sudo apt update
sudo apt install -y git build-essential cmake ninja-build ccache
sudo apt install -y libcurl4-openssl-dev
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp2、编译llama.cpp
cmake -B build -G Ninja -DCMAKE_BUILD_TYPE=Release \
-DGGML_NATIVE=OFF \
-DGGML_AVX=ON -DGGML_AVX2=ON \
-DGGML_F16C=ON -DGGML_FMA=ON \
-DGGML_AVX512=ON \
-DGGML_AVX512_VNNI=ON \
-DGGML_AVX512_VBMI=OFF \
-DGGML_AVX512_BF16=OFF
cmake --build build -j
#二代Cascade Lake 增了 AVX512_VNNI;BF16是Cooper Lake才有,VBMI从Ice Lake才有。
#Cooper Lake和Ice Lake都是三代4189至强,区别就是Cooper Lake仍然是14nm,Ice Lake才是真10nm三代xeon,价格不如直接上Emerald Rapids五代xeon3、运行推理脚本
#设置模型目录
MODEL="$HOME/桌面/gpt-oss-120b-GGUF/gpt-oss-120b-MXFP4-00001-of-00002.gguf"
#在llama.cpp编译目录运行
./build/bin/llama-cli -m "$MODEL" \
-i \
-c 4096 \
-b 256 \
-t $(nproc) \
--simple-io
#线程数 -t:先用 $(nproc) 跑一轮;双路 8259CL 往往 96 线程,若发现吞吐上不去(调度开销),再试物理核数(比如 48)。
#上下文 -c 与 批大小 -b:120B 内存、计算都很重。-c 4096/-b 256 是稳妥起步值;prefill 想更快可逐步把 -b 调大(512、768),但内存会涨。
96线程全部跑满,推理速度1秒3字左右,属于勉强可以使用级别,120b不添加联网本身不是聪明,但是比deepseek 671b勉强2.3token/s强太多了
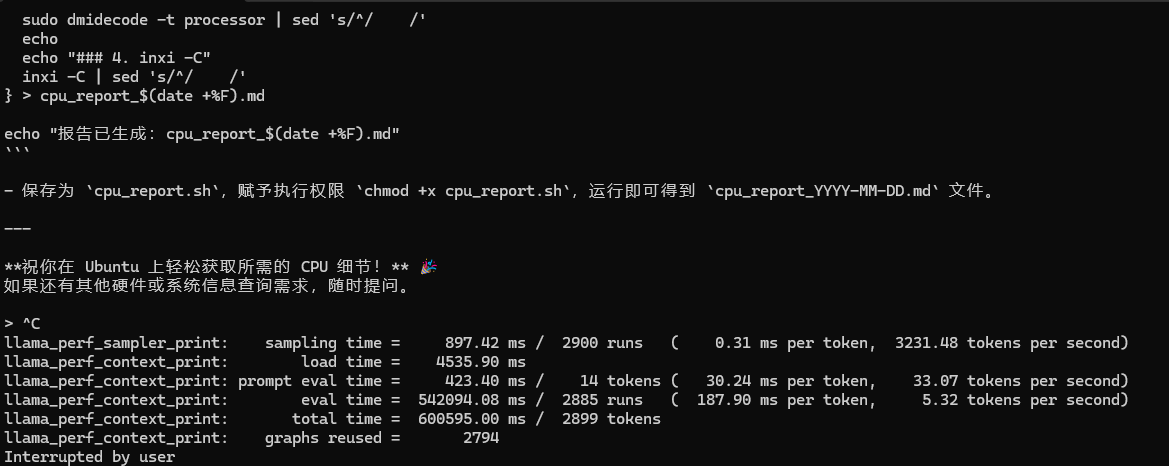
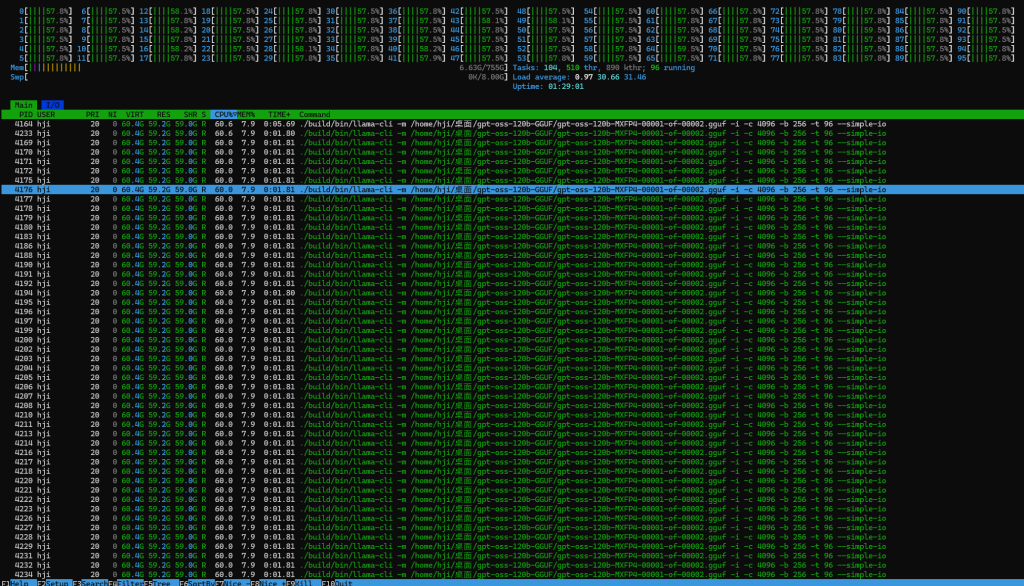
4、性能调优
那么线程数越多越好吗?尽管96线程满载看上去很厉害,但是核心计算性能其实不是非常重要,内存带宽是第一要素。纯cpu方案内存带宽是极大瓶颈,我们粗略计算一下单路带宽,因为Cascade Lake为6通道DDR4,因此64x6x2400/8/1024=112.5GB/s,双路远远达不到x2水平,要受到UPI总线限制,此速度喂满双路是完全不够的,从实际推理速度结果来看就可见一斑。另外avx512功耗过大,降频极为明显,因此我们重新编译了AVX2版本。从96线程的5.32t/s的结果来看,远远没有达到纯cpu推理的上限,因此我们将线程限制为15,关闭超线程,上下文增加到8192(8k),绑定cpu0,开启numa,运行以下推理命令:
MODEL="$HOME/桌面/gpt-oss-120b-GGUF/gpt-oss-120b-MXFP4-00001-of-00002.gguf"
CPUSET_PHYS=$(lscpu -e=CPU,CORE,SOCKET | awk '$3==0{if(!( $2 in seen)){printf (n++?",":"") $1; seen[$2]=1}}')
taskset -c "$CPUSET_PHYS" ./build-avx2/bin/llama-cli -m "$MODEL" -i -c 8192 -b 256 -t 15 --simple-io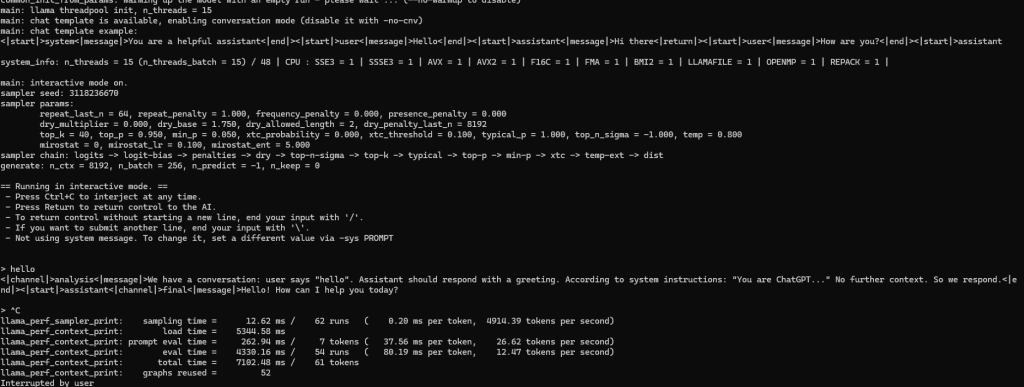
我们可以看到,此时推理速度高达12.5t/s,吊打96线程的5t/s,接近网页版deepseek水平。


测试